本次实验中共使用了5台华为云ECS,其中1台作为master节点,3台作为workers节点,1台作为观察用的机器。(由于绑定外网相关设置复杂,我们组开了同一地域的一个虚拟机专门用于访问其他四台机器的网页)除了观察用的机器是Windows Server 2012R2 64位简体中文版以外,其他的机器使用的都是Ubuntu Server 18.04。剩余四台主机的主机名、内网IP与公网IP如下。
vim /etc/profile # 编辑配置文件 source /etc/profile # 让这个配置文件生效
测试JAVA环境
1 2 3 4 5
root@ecs-master:/usr/java# java -version java version "1.8.0_291" Java(TM) SE Runtime Environment (build 1.8.0_291-b10) Java HotSpot(TM) 64-Bit Server VM (build 25.291-b10, mixed mode) root@ecs-master:/usr/java#
成功。
主节点安装Scala
安装
此处采取了官网deb包的安装方式。
1
apt-get install ./scala-2.12.15.deb
测试Scala环境
1 2 3 4 5 6 7 8
root@ecs-master:/usr# scala Welcome to Scala 2.12.15 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_291). Type in expressions for evaluation. Or try :help.
root@ecs-master:/usr/java# hadoop version Hadoop 3.2.2 Source code repository Unknown -r 7a3bc90b05f257c8ace2f76d74264906f0f7a932 Compiled by hexiaoqiao on 2021-01-03T09:26Z Compiled with protoc 2.5.0 From source with checksum 5a8f564f46624254b27f6a33126ff4 This command was run using /usr/java/hadoop-3.2.2/share/hadoop/common/hadoop-common-3.2.2.jar root@ecs-master:/usr/java#
# The java implementation to use. By default, this environment # variable is REQUIRED on ALL platforms except OS X! export JAVA_HOME=/usr/java/jdk1.8.0_291
root@ecs-master:/usr# spark-shell 21/10/15 23:59:50 WARN Utils: Your hostname, ecs-master resolves to a loopback address: 127.0.1.1; using 192.168.0.142 instead (on interface eth0) 21/10/15 23:59:50 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address 21/10/15 23:59:51 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://192.168.0.142:4040 Spark context available as 'sc' (master = local[*], app id = local-1634313599435). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3.0.3 /_/ Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_291) Type in expressions to have them evaluated. Type :helpfor more information.
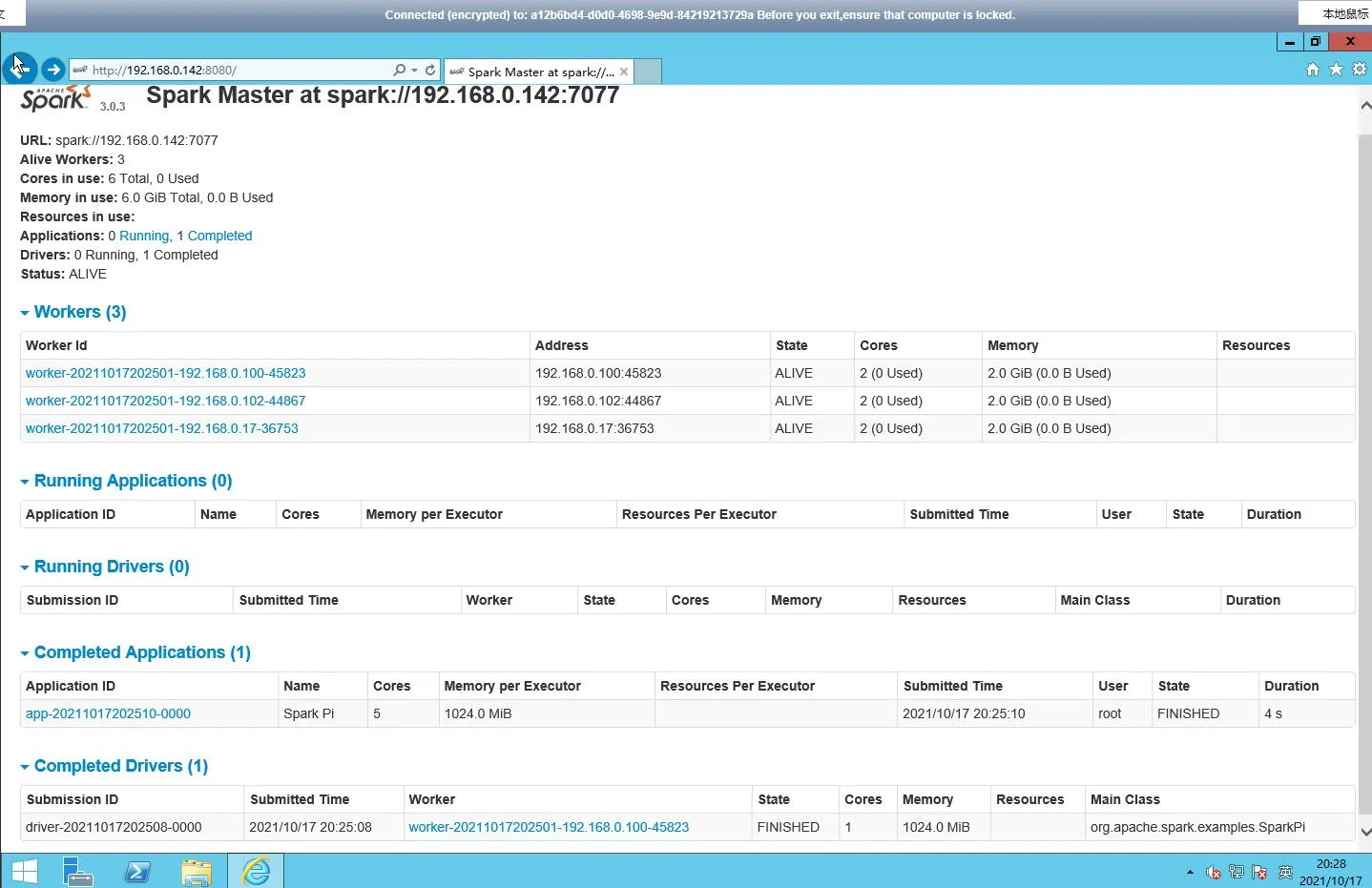
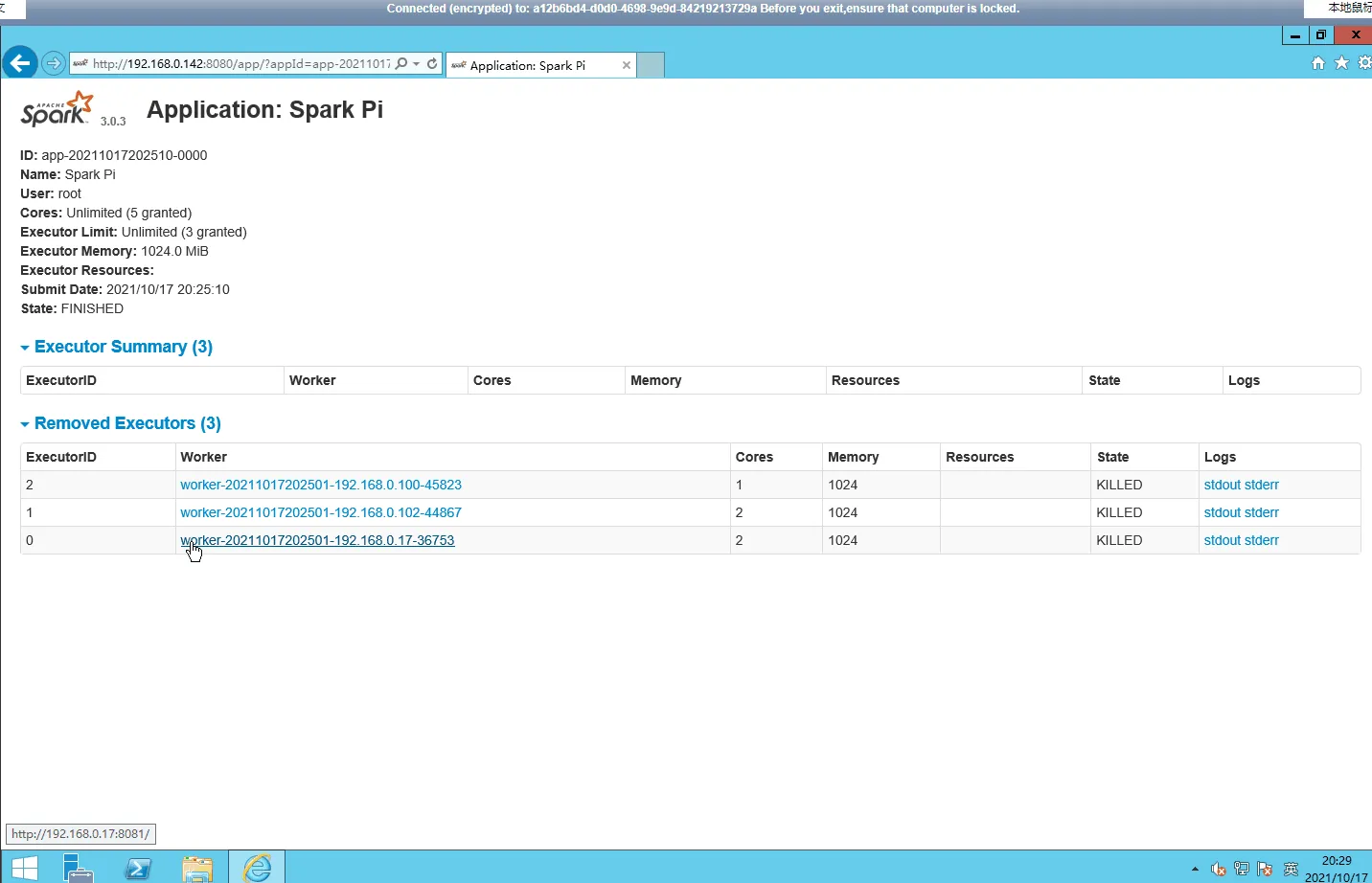
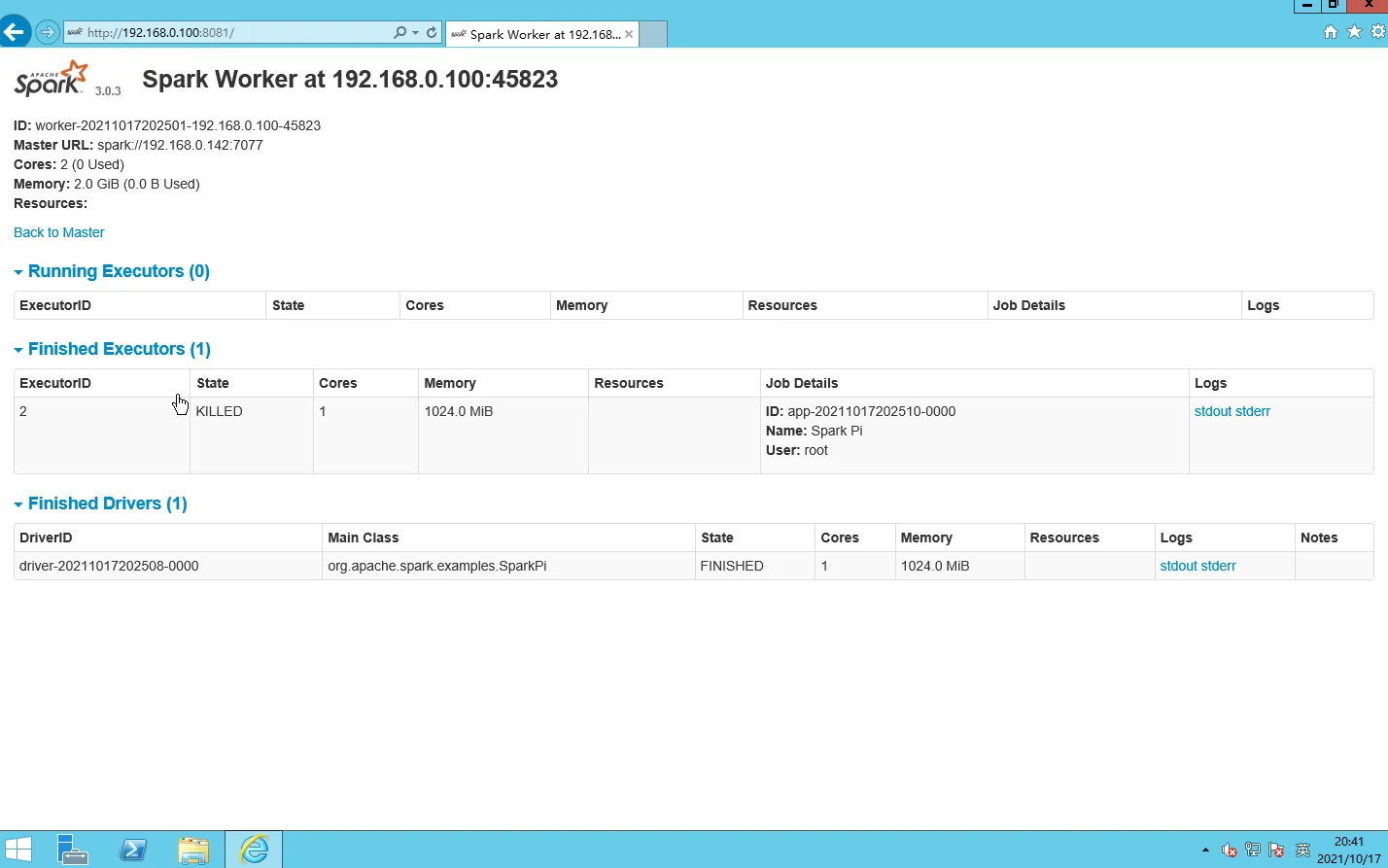
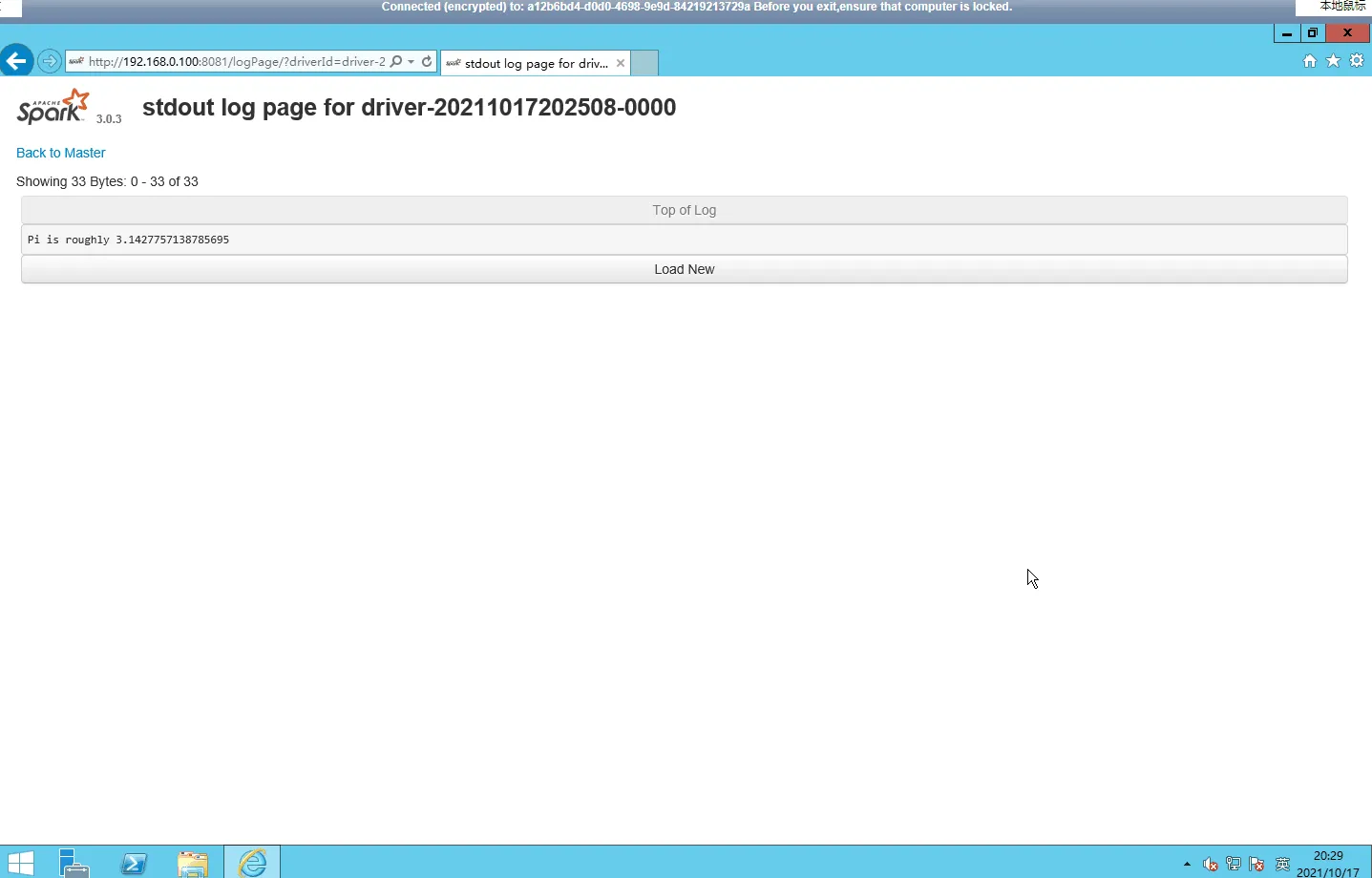
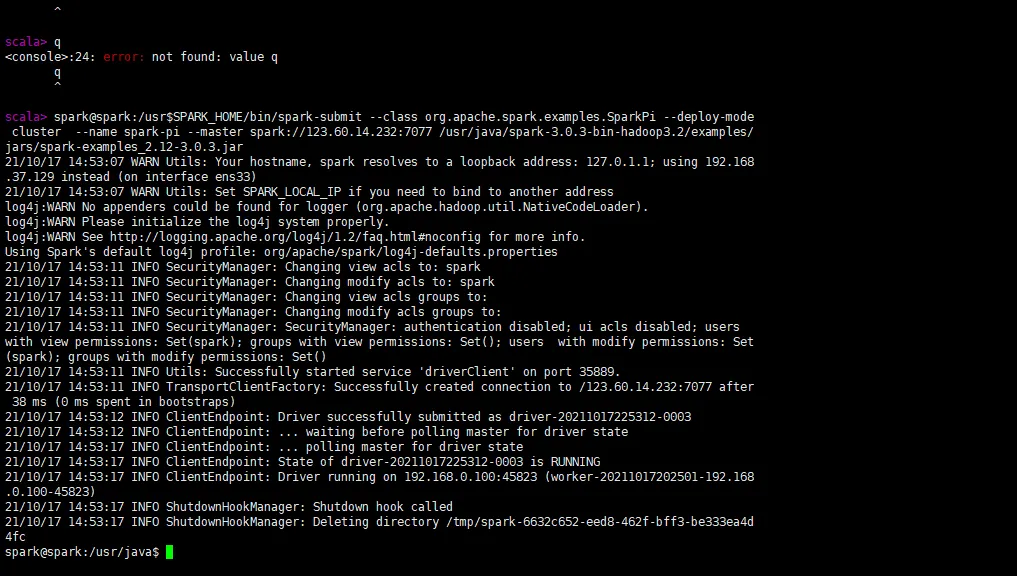
root@ecs-master:/usr/java/hadoop-3.2.2/sbin# $SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.SparkPi --deploy-mode cluster --name spark-pi --master spark://192.168.0.142:7077 /usr/java/spark-3.0.3-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.0.3.jar 21/10/17 20:25:07 WARN Utils: Your hostname, ecs-master resolves to a loopback address: 127.0.1.1; using 192.168.0.142 instead (on interface eth0) 21/10/17 20:25:07 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.NativeCodeLoader). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 21/10/17 20:25:07 INFO SecurityManager: Changing view acls to: root 21/10/17 20:25:07 INFO SecurityManager: Changing modify acls to: root 21/10/17 20:25:07 INFO SecurityManager: Changing view acls groups to: 21/10/17 20:25:07 INFO SecurityManager: Changing modify acls groups to: 21/10/17 20:25:07 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set() 21/10/17 20:25:08 INFO Utils: Successfully started service 'driverClient' on port 36051. 21/10/17 20:25:08 INFO TransportClientFactory: Successfully created connection to /192.168.0.142:7077 after 51 ms (0 ms spent in bootstraps) 21/10/17 20:25:08 INFO ClientEndpoint: Driver successfully submitted as driver-20211017202508-0000 21/10/17 20:25:08 INFO ClientEndpoint: ... waiting before polling master for driver state 21/10/17 20:25:13 INFO ClientEndpoint: ... polling master for driver state 21/10/17 20:25:13 INFO ClientEndpoint: State of driver-20211017202508-0000 is RUNNING 21/10/17 20:25:13 INFO ClientEndpoint: Driver running on 192.168.0.100:45823 (worker-20211017202501-192.168.0.100-45823) 21/10/17 20:25:13 INFO ShutdownHookManager: Shutdown hook called 21/10/17 20:25:13 INFO ShutdownHookManager: Deleting directory /tmp/spark-d5da4c1e-e685-4512-b9ac-ded68ae44883